
Duplicate Record Creation — The Invisible Twin Problem in Applications

If you’ve ever seen your application suddenly have two identical records where only one should exist — congratulations, you’ve met one of the most sneaky data integrity issues: Duplicate Record Creation.
It’s a silent troublemaker — doesn’t always crash your app, but it quietly pollutes your data, confuses analytics, and breaks user trust.
In this blog, let’s explore why duplicates happen, how to prevent them, and how to handle them gracefully in C# — all with a relatable real-world analogy.
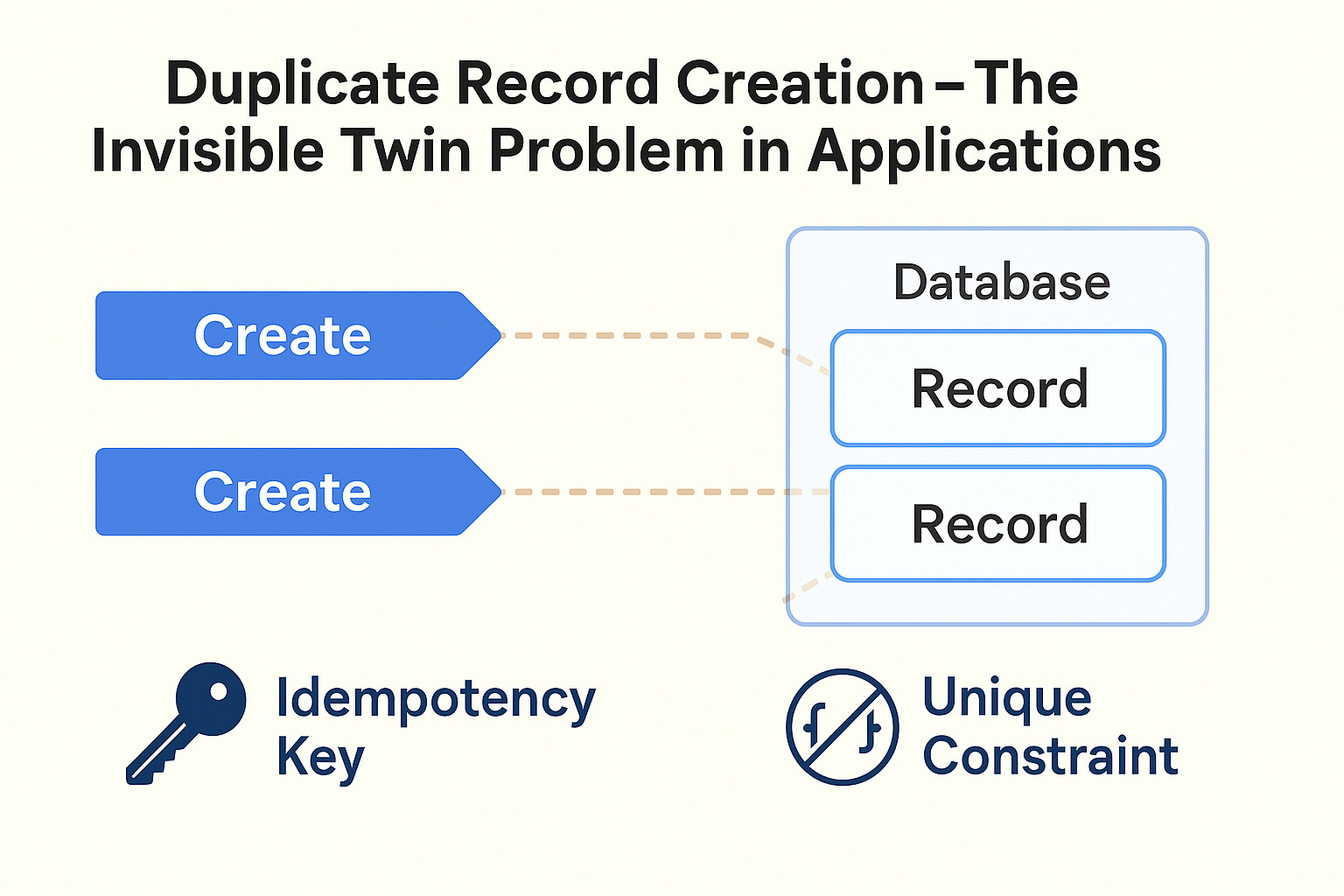
🎯 What Is the Duplicate Record Problem?
The duplicate record creation problem happens when two or more requests try to create the same record simultaneously, before either knows the other has already done it.
This is especially common when:
Multiple users perform the same action at the same time (like “Submit”).
Background jobs retry failed API calls.
Distributed services send the same data concurrently.
There’s no proper uniqueness enforcement at the database or application level.
🧠 Real-World Analogy — The Café Loyalty Card
Imagine a coffee shop running a loyalty program.
Every new customer gets a unique loyalty card.
Now, two baristas are onboarding customers into the system.
A customer named Alice signs up.
Barista 1 clicks “Create Card” — at the same time, Barista 2 does too.
Both requests reach the system almost simultaneously — before the database has confirmed the first insert.
Now Alice ends up with two loyalty cards — each valid, each counting rewards separately.
The result: happy Alice, unhappy system.
💥 The Root Cause — Concurrency
In technical terms, this happens because:
Two requests reach the API at nearly the same time.
The app checks “Does Alice already exist?”
Both see “No” (because the insert hasn’t committed yet).
Both create a new record.
🧩 A Simple Example — The Wrong Way
Let’s simulate this scenario with a basic C# API example.
public class Customer
{
public int Id { get; set; }
public string Email { get; set; } = default!;
}
public class CustomerService
{
private readonly AppDbContext _context;
public CustomerService(AppDbContext context)
{
_context = context;
}
public async Task<Customer> CreateCustomerAsync(string email)
{
// ❌ Step 1: Check if customer exists
var existing = await _context.Customers
.FirstOrDefaultAsync(c => c.Email == email);
if (existing != null)
return existing; // already exists, return existing record
// ❌ Step 2: Insert a new record
var customer = new Customer { Email = email };
_context.Customers.Add(customer);
await _context.SaveChangesAsync();
return customer;
}
}
This code looks fine — but it’s not thread-safe.
If two requests arrive simultaneously with the same email, both will pass the existence check before either saves, creating two identical records.
⚙️ The Correct Fix — Database-Level Protection
The first line of defense should always be the database constraint, because it’s atomic and reliable.
In your database schema (for example, SQL Server):
ALTER TABLE Customers ADD CONSTRAINT UQ_Customer_Email UNIQUE (Email);
Now, even if two requests sneak in, the database will reject one with a UniqueConstraintViolationException.
You can handle that gracefully in your C# code:
public async Task<Customer> CreateCustomerSafelyAsync(string email)
{
var customer = new Customer { Email = email };
_context.Customers.Add(customer);
try
{
await _context.SaveChangesAsync();
return customer;
}
catch (DbUpdateException ex) when (IsUniqueConstraintViolation(ex))
{
// Another process inserted it at the same time
return await _context.Customers.FirstAsync(c => c.Email == email);
}
}
private bool IsUniqueConstraintViolation(DbUpdateException ex)
{
return ex.InnerException?.Message.Contains(”UQ_Customer_Email”) ?? false;
}
💡 Lesson: Let the database enforce uniqueness — your app can react to violations, not preemptively prevent them.
🧰 Application-Level Safeguards
While the database constraint is the foundation, you can strengthen your app with additional safeguards:
1️⃣ Use a Lock or Semaphore (for in-memory safety)
If your app handles many parallel requests in a single instance:
private static readonly SemaphoreSlim _lock = new(1, 1);
public async Task<Customer> CreateCustomerWithLockAsync(string email)
{
await _lock.WaitAsync();
try
{
var existing = await _context.Customers
.FirstOrDefaultAsync(c => c.Email == email);
if (existing != null) return existing;
var customer = new Customer { Email = email };
_context.Customers.Add(customer);
await _context.SaveChangesAsync();
return customer;
}
finally
{
_lock.Release();
}
}
This ensures that only one thread executes the insert logic at a time — though it’s per instance, not across multiple servers.
2️⃣ Use a Distributed Lock (for multi-server apps)
In distributed systems, where multiple app instances may run, consider using a distributed lock, e.g., Redis RedLock.
using (var redLock = await _distributedLockFactory.CreateLockAsync(”customer:create:” + email, TimeSpan.FromSeconds(5)))
{
if (redLock.IsAcquired)
{
// Same logic inside here — only one node can hold the lock
}
}
This prevents duplicate inserts even when requests hit different servers.
3️⃣ Use Idempotency Tokens
For APIs that may receive retries (like payment gateways or user submissions), use idempotency keys — unique tokens that ensure the same operation isn’t performed twice.
Each client includes a header like:
Idempotency-Key: 39a6dbf2-9b8f-4b72-8f40-c8a9039c5a55
Your API stores and checks this key before creating a record.
🚦 Combined Strategy — Real-World Architecture
Let’s put it together with a real-world analogy:
Imagine you’re building an online registration system for event attendees.
To prevent duplicate sign-ups:
At the app level: use idempotency tokens (prevent resubmission).
At the server level: use distributed locks (prevent concurrent inserts).
At the database level: enforce a unique constraint (catch final conflicts).
That’s a three-layer safety net — no more ghost twins in your database.
📊 Bonus: Detecting Existing Duplicates
If you already have duplicate records (say, from older systems), you can clean them using C# + LINQ:
var duplicates = _context.Customers
.GroupBy(c => c.Email)
.Where(g => g.Count() > 1)
.SelectMany(g => g.Skip(1));
_context.Customers.RemoveRange(duplicates);
await _context.SaveChangesAsync();
🏁 Final Thought
The duplicate record problem isn’t just about databases — it’s about timing and coordination.
In distributed systems, milliseconds matter — two inserts 20ms apart can cause silent data corruption if you don’t prepare for it.
So, treat duplicates like a hidden twin — you can’t stop users from clicking twice, but you can stop your app from accepting it twice.
In short:
“You can’t control user clicks, but you can control system commits.”